Reading Execution Plans, Part 2: Retrieving Data
Now that we have our execution plan, let's talk about data. And we're going to start at the opposite place from how we start reading execution plan, because the easiest way to start talking about data is to talk about how we get it. There are technically six different nodes that constitute retrieving data from the database tables, but really, there are only two different ways to get the data and the other differences are related to the structure of the data on disk.
The two different ways to access the data are scan and seek. In order to explain the difference between the two, I need to get into how to access data in a tree data structure. I know if you're reading this, you're a developer, and you probably already know how trees work, but please bear with me, because it is key to understanding the difference between a scan and a seek.
Scan

Let's take the usual example of a phone book. Now, obviously, there are several ways that you can search through a phone book. You can start with the first name in the book, in the A's, and proceed through every name until you find the one you're looking for. This is the behavior of a scan. With any scan, SQL will start at the first record and return every record it finds until either it runs out or the parent is no longer asking for records.
There are three types of Scans: Table Scan, Clustered Index Scan, and Index Scan. The only difference between the three is where the data comes from (heap table, clustered index, and non-clustered index, respectively).
Warning: A Table Scan is only used when there is no clustering index on the table; this is a always something to pay attention to. All tables should have a clustering index, so if you see a Table Scan, you should definitely figure out what the clustering index should be and add one.

One performance enhancement that is added to the Scan nodes is that occasionally a search filter will be performed in the Scan itself. The Scan will still read every row, in order to evaluate the predicate, but it will reduce the number of records any parent nodes will have to process. If the predicate is used, it can be see by hovering over the node, which will show a yellow hover window with a Predicate line as in this image; or by going to the node Properties, which will have a Predicate row.
Seek

Going back to the phone book example, if I knew that I was looking for my own last name, Turner, it would take forever to search through the phone book. However, we all know that there's a better way: first, open a random page roughly 3/4 through the book and check the first name; move forward or backwards one or more pages based on whether that name is before or after Turner; until the first name on the page is close to Turner, and then search for Turner.
In many ways, this is how the SQL server will execute a seek. If you have an index on a set of columns, then the server will keep an ordered tree based on those column. Finding an element is much quicker when navigating down a tree instead of searching through every element. The SQL server also keeps pointers to neighboring leaf nodes in each leaf, so that range searches can be done through a Seek.
There are three versions of the Seek: Clustered Index Seek, Index Seek, and Key Lookup. The Clustered Index Seek and the Index seek are both looking up data in an Index.
The Key Lookup is special; it is the same thing as a Clustered Index Seek (it uses a seek to return data from a clustered index), but it is displayed differently in an execution plan to highlight an important fact: that an Index already returned some data from the table, and second seek had to be done against the same table to return more data. Depending on how much data is requested from the Key Lookup, performance may be improved by including additional data in the Index that originally queried data from the table.
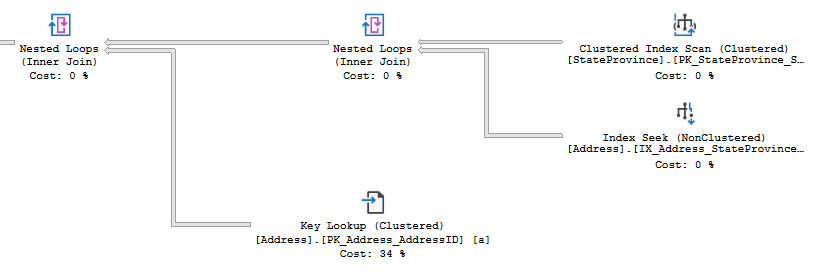
To better explain, look at this portion of an execution plan. Notice that there is an Index Seek against the Address table, on index [IX_Address_StateProvinceID], and a Key Lookup against [PK_Address_AddressID]. In this case, the [IX_Address_StateProvinceID] index was useful to find specific records in the Address table, but did not provide all of the data requested by the query. To improve performance, it may be valuable to update the index to include the additional data requested by the Key Lookup.
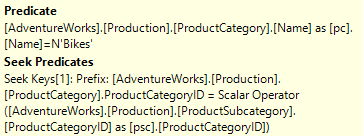
Additional data on the Seek can be found by hovering over the node, or by looking at the node properties. A Seek will always have a Seek Predicates section, which identifies how the Index was used to seek for data. Similar to the Scan, it may also have a Predicate section which is used to filter the data before processing by the rest of the query execution.