Reading Execution Plans, Part 4: Processing Data
So now we have some data, and we've combined it with other tables. However, sometimes we need to compute new columns based on data from other columns, or we weren't able to filter data at the table. Now we have some Processing nodes where we can do whatever else we need to do with the data before delivering to the user.
Compute Scalar Node
The Compute Scalar node is where any new columns get computed; the new columns are added to the row, and the row is immediately returned. Non-persisted computed columns defined in a table schema are also calculated in a Compute Scalar node. The reason this work is not being done in the Select node is because this operation can be necessary to have the data required to operate other nodes, such as the Filter node.
Take the following query: select * from SalesOrderHeader where datediff(d, OrderDate, ShipDate) > 5. The value being compared (datediff(d, OrderDate, ShipDate)) does not exist in the table, so it must be computed before the record can be filtered. By having a dedicated Compute Scalar node, everything that can be computed as a new column can be consolidated to a single node which can be used anywhere in the execution plan.
Additional data about the Compute Scalar node can be found in the node properties, shown here. The Defined Values element can be expanded to reveal all of the columns that were computed and added to the data row in this node.
IEnumerable<DataRow> ComputeScalarNode(IEnumerable<DataRow> data)
{
foreach (var row in data)
{
row["SalesOrderNumber"] = "SO" + convert(string, row["SalesOrderID"]);
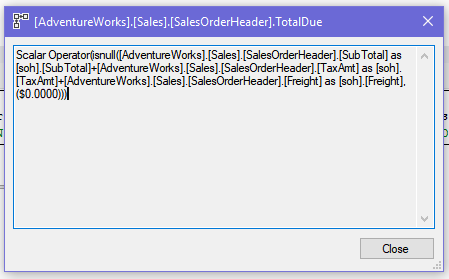
row["TotalDue"] = isnull(row["SubTotal"] + row["TaxAmt"] + row["Freight"], 0.00);
yield return row;
}
}
Filter Node
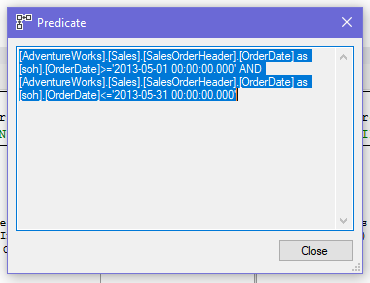
The Filter node should be fairly obvious. When asked for a row, it returns the next row that matches the predicate. When optimizing a query, the optimizer does not treat a where clause as a single predicate, but will work with each condition independently. Depending on where the data exists and how many records the Filter is expected to remove, the individual conditions may be found in the same Filter node or in separate Filter nodes. Additional detail can be found on the whole predicate used for the Filter node can be found in the node properties.
IEnumerable<DataRow> FilterNode(IEnumerable<DataRow> data)
{
foreach (var row in data)
{
if (predicate(row) == true)
yield return row;
}
}
Sort Node
The Sort node, as it's name suggests, sorts data before returning data to it's parent node. Since sorting is an operation that requires viewing all of the data, once asked for any data at all, the Sort node will buffer all of the records from it's input data. If possible, the sort operation will be handled in memory; however, if sorting a large amount of data, the data will be saved to a temporary table in tempdb before sorting. For this reason, Sort nodes can be an important node to look for when reading an execution plan.
There is a sub-version of the Sort Node that will take advantage of a provided top clause. Certain algorithms can be used for in-memory searching of the top n elements of a data set. This would reduce the amount of work required by not having to sort the entire data set for return.
IEnumerable<DataRow> SortNode(IEnumerable<DataRow> data)
{
var buffer = new List<DataRow>();
foreach (var row in data)
buffer.Add(row);
buffer.Sort();
foreach (var row in buffer)
yield return row;
}
Top Node

The Top node will limit output to the first N or N% of the rows given. An important thing to note here is that the Top node does not require a Sort node to come before it- if the data is unsorted, it will still return the first N records. This is because sorting is expected to have already occurred via another process.
If the query has an order by clause that matches the ordering of the index, then there will not be a Sort node. Instead, the index will provide data already sorted, and a Top node will be used to directly limit the amount of data.
IEnumerable<DataRow> TopNode(IEnumerable<DataRow> data)
{
var counter = 0;
foreach (var row in data)
{
yield return row;
counter++;
if (counter == N)
yield break;
}
}
Select Node
Finally, we have the Select node. The Select node is the most important node, because it handles delivering data to the client. In a select statement, it is always the root of the tree, the final node at the top-left of the diagram. The Select node is very simple, all it does is iterate data from the child node below it and deliver it to the client. I've included some pseudo-code below as example.
Now part of what's so interesting about the Select node is what is not being done here. The Select node does not buffer the data in any way (although the network code does do buffering to improve network performance), it does not do any computations or column generation, it does not filter the data in anyway. It has the singular purpose of handing data to the client. Instead, these other functions are done by the next few nodes we're going to talk about.
Also, no matter how many times the keyword select is listed in the original query, there will only be one Select node. Once the query has been parsed, any CTEs and sub-queries are rewritten as part of the larger query.
void SelectNode(SqlClient client, IEnumerable<DataRow> data)
{
foreach (var row in data)
{
row.TrimAndRenameColumns();
client.SendRow(row);
}
}